Google Prediction API
AI model development and deployment for improved operations.
Efficient engine for serving large language models with speed.
Vllm operates as an inference and serving engine designed to efficiently manage large language models.…
Read more
AI model development and deployment for improved operations.
Memory-efficient model for AI applications with quantized weights.
Cloud-based AI infrastructure for scalable model deployment.
Lightweight framework for efficient AI model deployment on edge devices.
Optimizes AI model inference for real-time applications.

Access thousands of powerful Nvidia GPUs for AI projects.
Fast and reliable access to scalable AI model deployment.

Centralized management for AI model deployment across environments.

Collaborative environment for evaluating large language models.
Access over 100 language models with ease and reliability.
Open-source portal for managing and optimizing LLM interactions.
Evaluate AI applications with comprehensive testing tools.
Manage and deploy AI models seamlessly across environments.
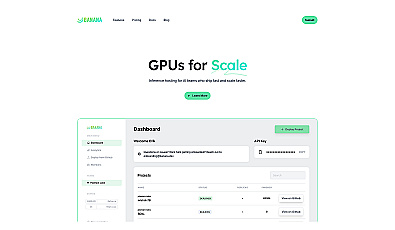
Efficient GPU resource management for AI model deployment.
On-demand computing resources designed for AI workloads.
An open-source framework for monitoring AI model performance.
Create and monetize customized AI language models for various needs.

Unified access point for comparing AI language models.
Streamlined deployment of machine learning models across environments.

Infrastructure-as-code for deploying machine learning models.
Streamlined performance monitoring for AI applications.
Streamlined management for AI model deployment and monitoring.

Deploy AI models quickly and efficiently without technical hurdles.