Apple Create ML
User-friendly machine learning model development for Mac users.
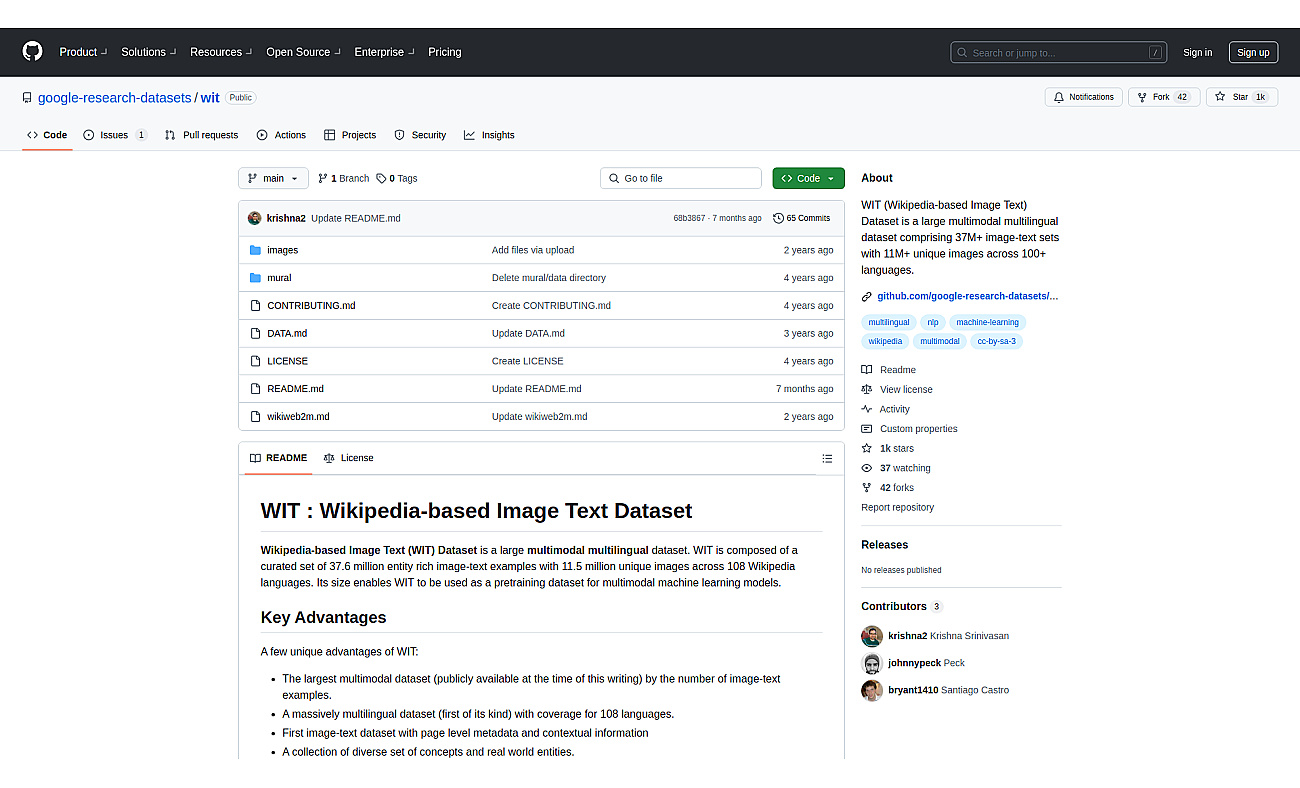
A large dataset of image and text pairs for AI training.
WIT Dataset is a comprehensive collection that includes over 37 million image and text pairs sourced from Wikipedia. This dataset is notable for its diverse coverage, spanning more than 100 languages.
With 11 million unique images linked to textual descriptions, it serves as a rich resource for developers and researchers working on machine learning projects.
By utilizing WIT Dataset, one can train models to better understand and analyze both visual and written content simultaneously. This capability opens doors to various applications, such as enhancing multilingual content analysis and improving image search results.
It plays a significant role in advancing artificial intelligence and supporting multimodal learning initiatives.
Based on overlapping tasks and related categories.
User-friendly machine learning model development for Mac users.
JavaScript library for building machine learning models in web applications.
Conversational search for quick, accurate data retrieval.

A comprehensive collection of diverse text datasets for training.
C++ library for advanced machine learning and image processing.
Run advanced language models directly on personal devices.
Discover other similar tools and compare features