Kyligence Copilot
Intelligent data assistant for quick and easy insights.
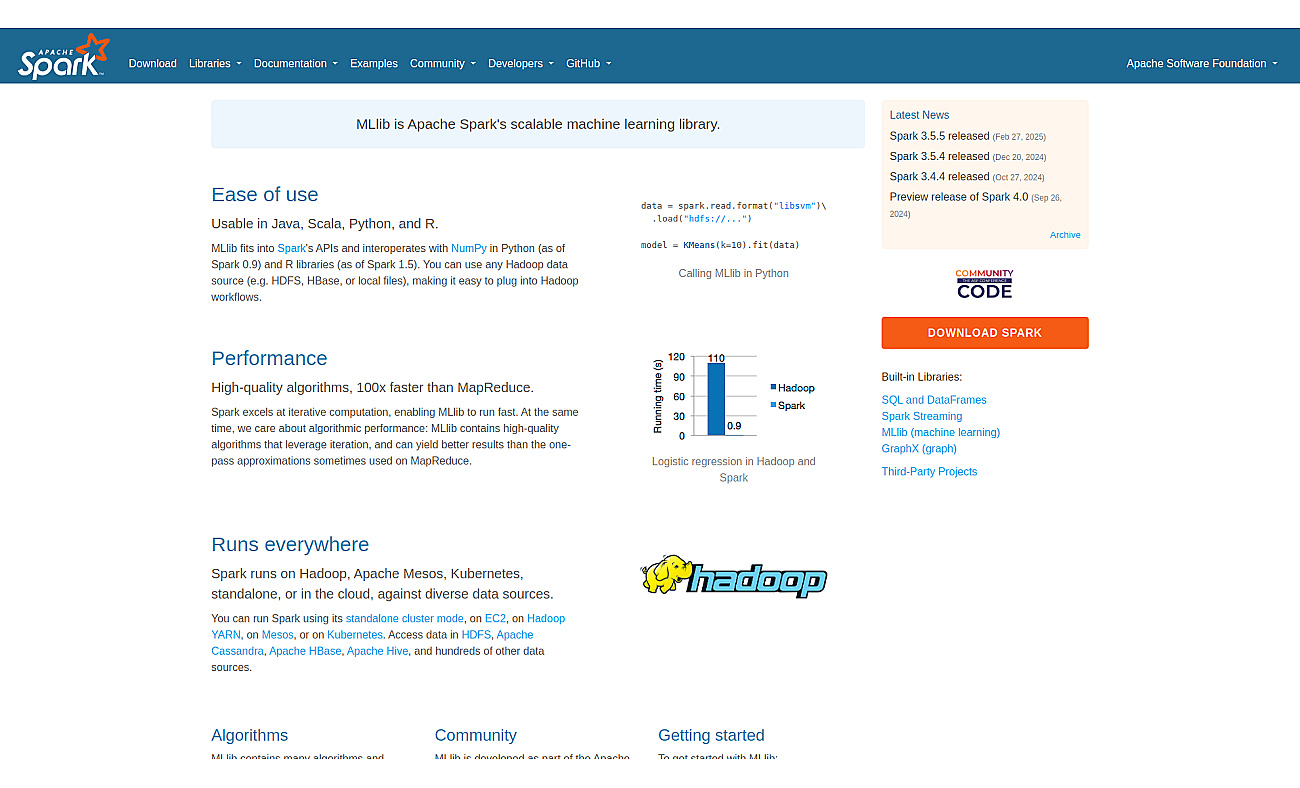
Scalable machine learning library for big data analysis.
This library provides machine learning capabilities designed for big data environments. With straightforward access to various algorithms for classification, regression, and clustering, it enables data scientists and analysts to create and implement models efficiently.
Organizations can leverage its features to analyze large datasets and derive meaningful insights quickly.
This leads to improved decision-making and refined processes.
The library supports multiple programming languages and integrates seamlessly with Apache Spark, making it a valuable asset for automating tasks like customer segmentation, product recommendations, and fraud detection. By utilizing this library, businesses can enhance their analytical capabilities and respond better to market demands.
Based on overlapping tasks and related categories.
Intelligent data assistant for quick and easy insights.
Natural language data querying for everyone.
AI-driven assistant for coding in interactive notebooks.
No-code predictive analytics for swift data-driven decisions.
Transform data into insights with user-friendly analytics.
Transform database queries into simple, conversational insights.
Discover other similar tools and compare features